

What I am going to do and Why ?
Sri Lanka will face a presidential election by the end of this year, but in order to understand how people have voted so far in previous elections we need data. I was hoping this data could be in opendata initiative website, unfortunately I was not happy with the results. Only one set of data was presented here, which was for District Registered Electors from 2007 - 2017.
Where is the data !
Well I did not give up, because there is the Elections Commission website. Hopefully, I found the data which was needed under the title Presidential Election Results. Still there is an issue where all the election results are in pdf files. Each pdf file had data of each presidential election. After skimming through these six election results in pdf files it was clear that not all of them have the same format or pattern in representing the data. But this will not be an issue if we had the data in a csv or excel file which could be useful for researchers or investigative journalists.
So my knowledge as an R programmer will come in handy for extracting tables from these pdfs. Also this blog post is about extracting data from the pdf file of Presidential Election results in 2015. I will be using the packages pdftools, stringr, data.table and splitstackshape.
Simplifying and Solving
pdftools to extract information from pdf files, stringr for string manipulation such as identify, remove or match patterns, data.table to create the data-set, finally splitstackshape for critical column and row manipulation using patterns in text. These packages are much useful in creating one strong data-set of Presidential Election results from year 2015.
In a presidential election all contestants are voted from all electorates through out the country, therefore in all tables the information looks the same. This same type of information is the contestants names, valid votes, rejected votes, total polled and registered electors. So extracting data is much more easier in a presidential election than a parliament election. This year 2015 presidential election pdf file of 111 pages can be classified in-to three groups based on pages.
First group includes pages 1 and 111 where no data needs to be extracted. Second group is for pages which has only one table, Final group is with pages which have two tables per page(which is a lot). Small note is that a new district result begins in a new page that is why we have pages with one table. Main heading is district name but only on top of the page, secondary heading is Electorate name for each table, but this is not the case for all tables. There are three types of tables, which are tables for electorate votes, district postal votes and final district results. Below are figures of proof.
Page types

No Info
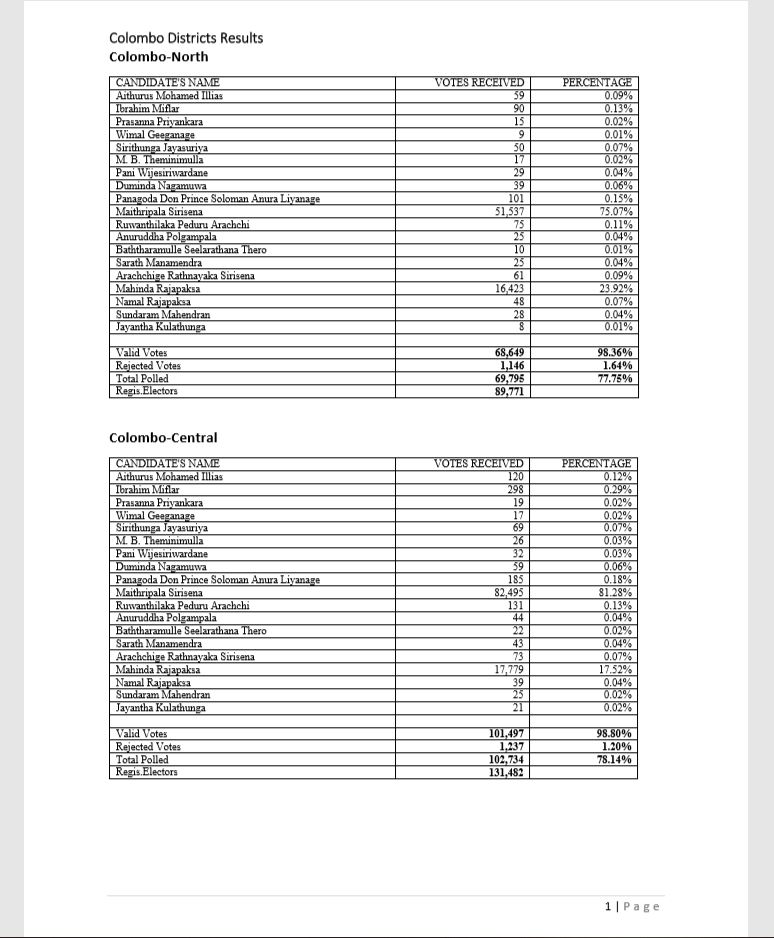
Two Tables
One Table
Table types
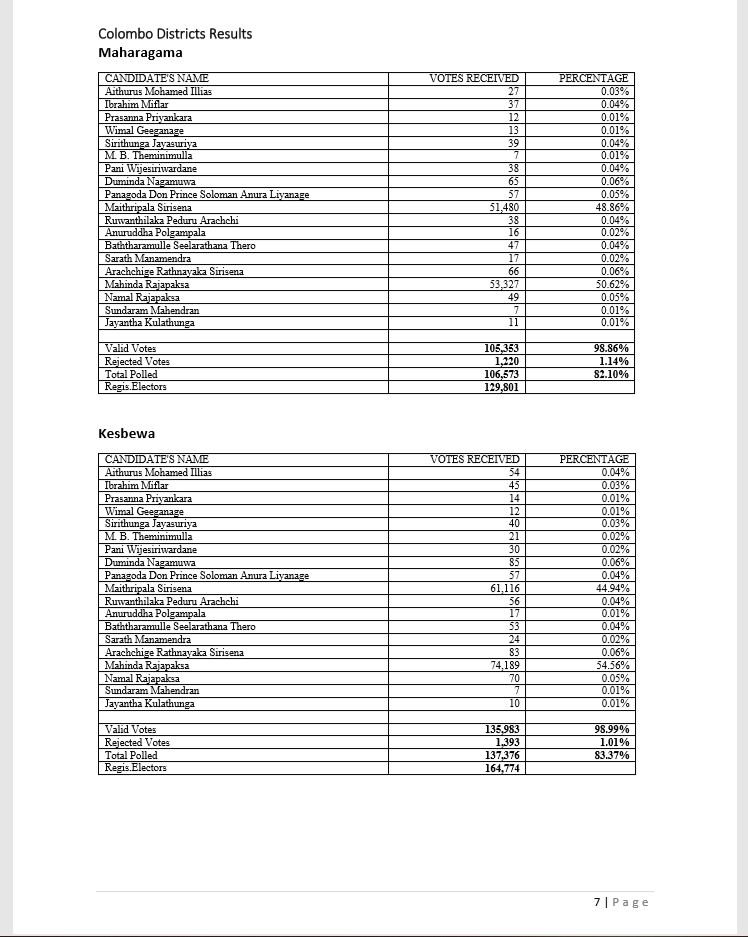
Two Electorate Results
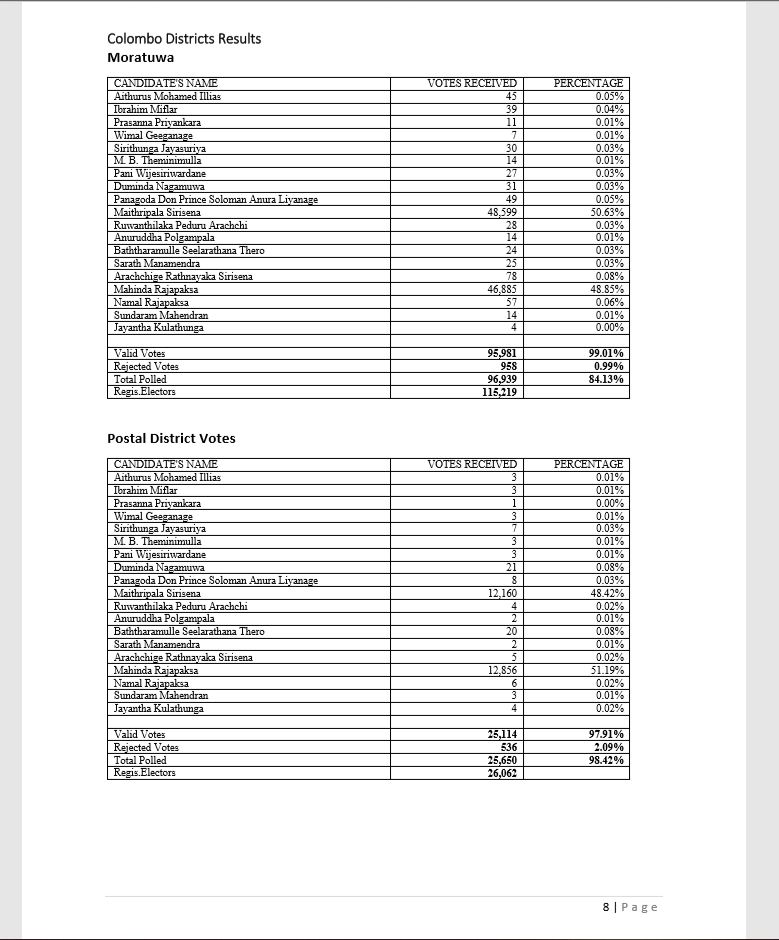
One Electorate and Postal Votes
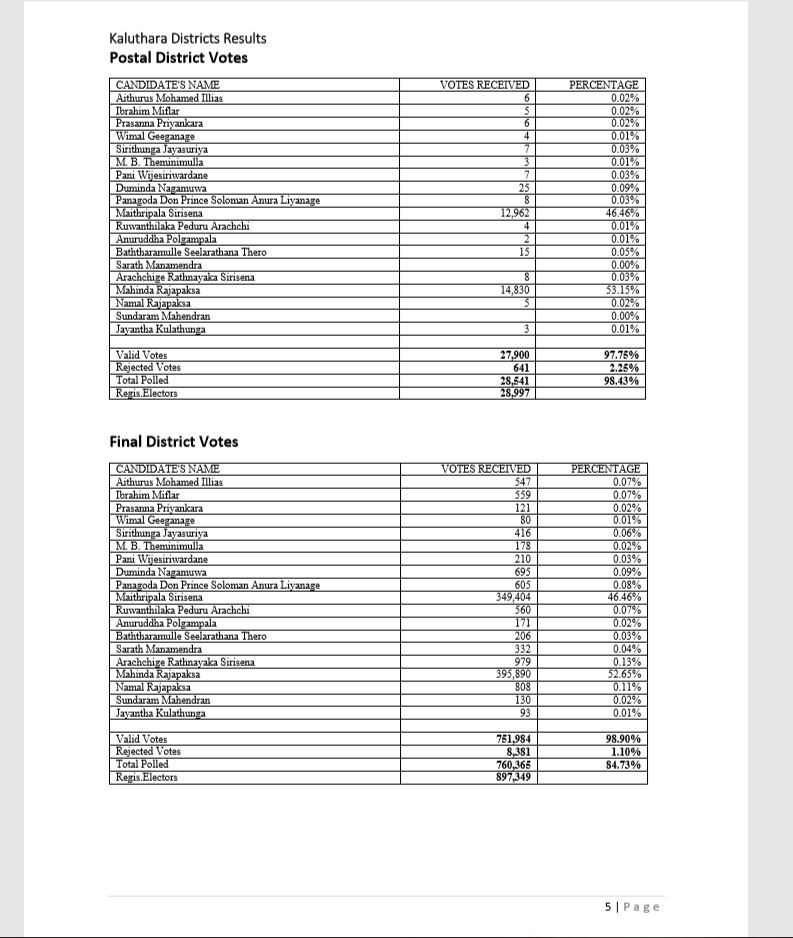
Postal Votes and Final District Results
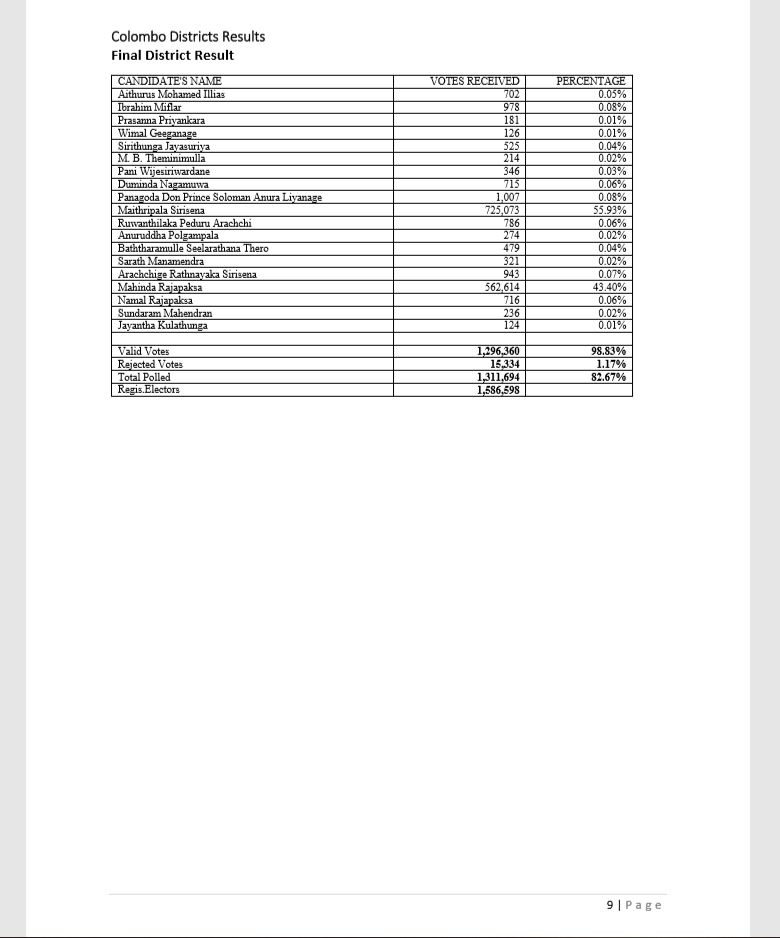
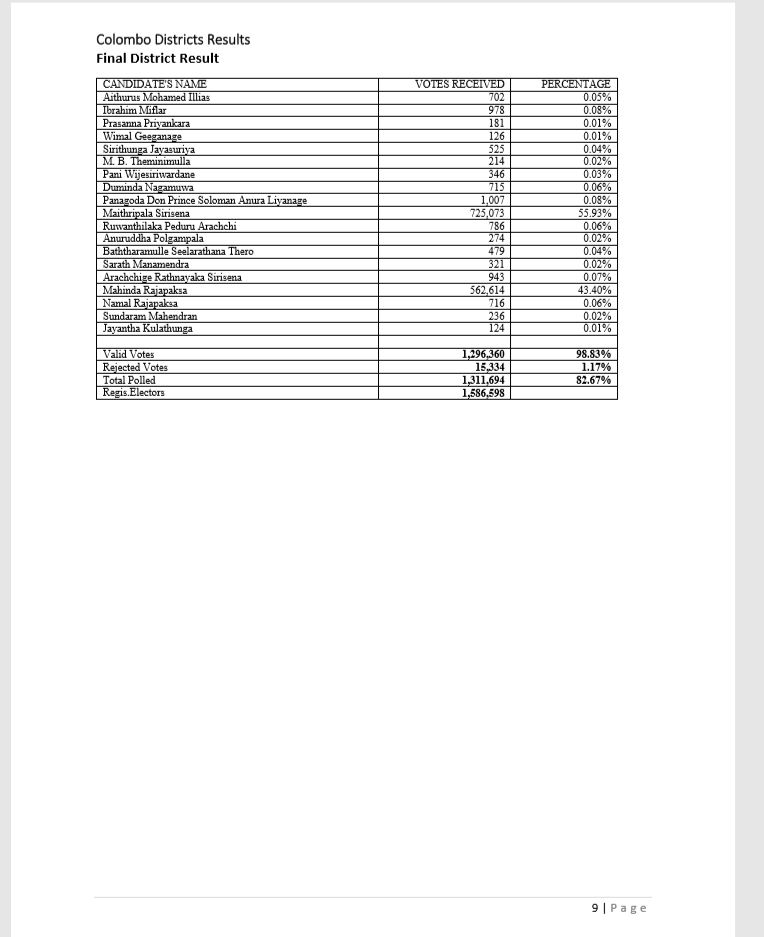
Final District Results only
So from these tables only we need to extract information and create one large data-set.
Programming Part
I shall divide the data extraction in-to two parts, first extract data from two table pages and next extract data from one table pages. For these two situations I will develop two functions. Both functions are similar except for the part with number of tables.
I shall only discuss the two table situation here(but will include code for one table extraction).
Step 1
Using the pdf_text function on the pdf file we will produce a character class output where each page is represented by a list(so 111 lists in this one output). Now consider one list which represents a page but it is still one line character. Convert this one line character into a multiple row list using str_split function and *pattern. So for the first table the information is from row 4 to 26 and second table data is from row 29 to 51.
# load the packages
library(pdftools)
library(stringr)
library(splitstackshape)
library(data.table)
# load the file
SL_PE_2015<-pdf_text("PresidentialElections2015.pdf")
page<-2
# split the one large list into a data frame of lines and separate them into two tables
table1<-data.table(str_split(SL_PE_2015[[page]],"\n")[[1]][4:26])
table2<-data.table(str_split(SL_PE_2015[[page]],"\n")[[1]][29:51])
# name the only column in these two data tables
names(table1)<-"hello"
names(table2)<-"hello"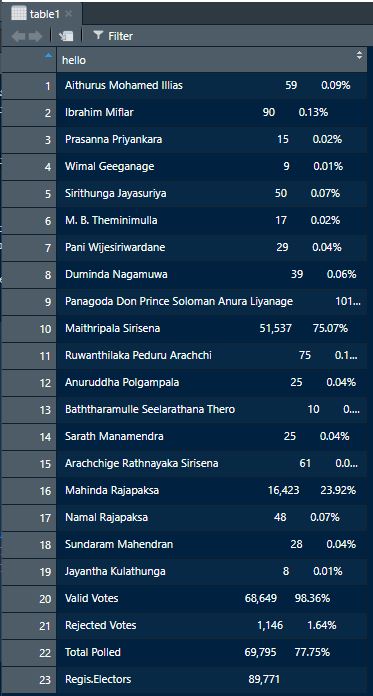
Now we have two one column data-frames with exact rows as the page of the pdf file we are extracting.
Step 2
Beginning information in these two tables contain the same information as mentioned earlier. So after removing this information we will be limited to another one column data-table but now only with votes and percentage values. This one column table can be separated by column splitting based on the pattern " ".
# creating the list with same type of information
Names=c("Aithurus Mohamed Illias","Ibrahim Miflar","Prasanna Priyankara",
"Wimal Geeganage","Sirithunga Jayasuriya","M. B. Theminimulla",
"Pani Wijesiriwardane","Duminda Nagamuwa",
"Panagoda Don Prince Soloman Anura Liyanage",
"Maithripala Sirisena","Ruwanthilaka Peduru Arachchi",
"Anuruddha Polgampala","Baththaramulle Seelarathana Thero",
"Sarath Manamendra","Arachchige Rathnayaka Sirisena",
"Mahinda Rajapaksa","Namal Rajapaksa","Sundaram Mahendran",
"Jayantha Kulathunga","Valid Votes","Rejected Votes",
"Total Polled","Regis.Electors")
# first using the above list remove the first column info
# then split all rows of one column into two columns based on " " pattern
Top<-cSplit(lapply(table1, function(x) str_remove(x,Names)),"hello"," ")
Bottom<-cSplit(lapply(table2, function(x) str_remove(x,Names)),"hello"," ")
# Extract the information of sub heading above each table by removing the pattern "\r"
Name1<-str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][2],"\r")
Name2<-str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][27],"\r")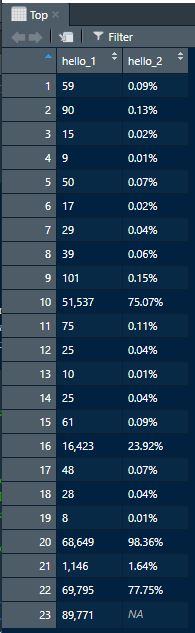
Step 3
Now create a proper table with three columns which has that same type of information, votes(with commas) and percentages (with percentage sign). Well by creating these Top1 and Bottom1 tables we will remove the percentage sign. Then we will remove the commas(,) in votes columns and convert them into numeric class. Further, even though the percentage column looks numeric it is not. To resolve it we shall convert these values also from factor to character and then finally to numeric.
# creating the new dataset with three columns without percentage sign
Top1<-data.table("ColumnNames"=Names,"Votes"=Top$hello_1,"Percentage"=str_remove(Top$hello_2,"%"))
Bottom1<-data.table("ColumnNames"=Names,"Votes"=Bottom$hello_1,"Percentage"=str_remove(Bottom$hello_2,"%"))
# remove the commas from votes columns and convert them to numeric class
Top1[,2] <- lapply(Top1[,2], function(x) as.numeric(as.character(str_remove_all(x,","))))
Bottom1[,2] <- lapply(Bottom1[,2], function(x) as.numeric(as.character(str_remove_all(x,","))))
# convert the percentage values to numeric class
Top1[,3]<-lapply(Top1[,3], function(x) as.numeric(as.character(x)))
Bottom1[,3]<-lapply(Bottom1[,3], function(x) as.numeric(as.character(x)))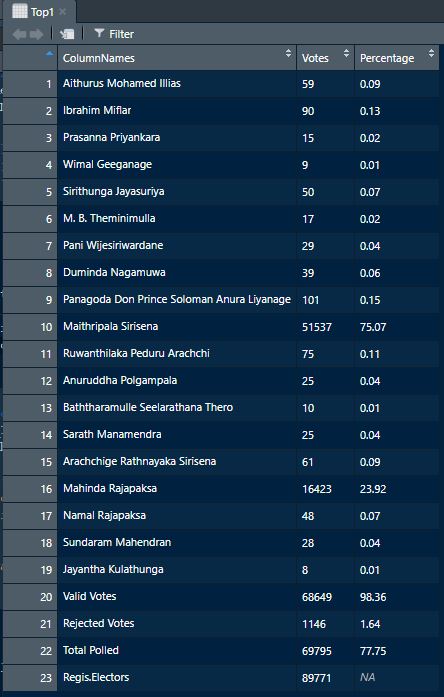
Step 4
Now our final tables are prepared. We shall name the columns. First column is for year, second column is for district name, third column is for that same type of information, fourth column is for number of votes and final column is for the percentage values.
Electorate1<-data.table("Year"=2015,
"District"=str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][1],
" Districts Results\r"),
"Electorate"=Name1,"ColNames"=Top1$ColumnNames,"Votes"=Top1$Votes,
"Percentage"=Top1$Percentage)
Electorate2<-data.table("Year"=2015,
"District"=str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][1],
" Districts Results\r"),
"Electorate"=Name2,"ColNames"=Bottom1$ColumnNames,"Votes"=Bottom1$Votes,
"Percentage"=Bottom1$Percentage)Finally, we have extracted two clear tables under the name Electorate1 and Electorate2. First three table types mentioned above can be extracted now.
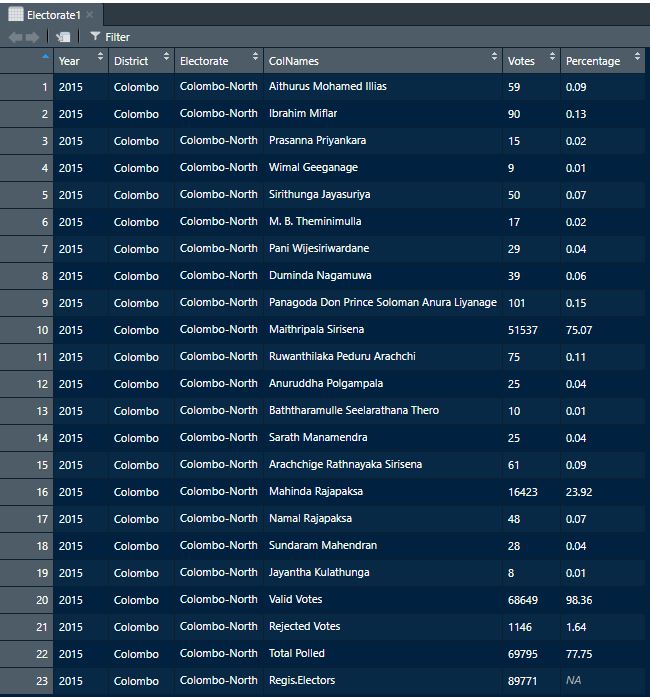
One Complete Function
Combining the above 4 steps we can create one function where the input is page number and the resultant will be a data-table of one page information but of two tables in the pdf file.
Extract_twotable<-function(page)
{
table1<-data.table(str_split(SL_PE_2015[[page]],"\n")[[1]][4:26])
table2<-data.table(str_split(SL_PE_2015[[page]],"\n")[[1]][29:51])
names(table1)<-"hello"
names(table2)<-"hello"
Names=c("Aithurus Mohamed Illias","Ibrahim Miflar","Prasanna Priyankara",
"Wimal Geeganage","Sirithunga Jayasuriya","M. B. Theminimulla",
"Pani Wijesiriwardane","Duminda Nagamuwa",
"Panagoda Don Prince Soloman Anura Liyanage",
"Maithripala Sirisena","Ruwanthilaka Peduru Arachchi",
"Anuruddha Polgampala","Baththaramulle Seelarathana Thero",
"Sarath Manamendra","Arachchige Rathnayaka Sirisena",
"Mahinda Rajapaksa","Namal Rajapaksa","Sundaram Mahendran",
"Jayantha Kulathunga","Valid Votes","Rejected Votes",
"Total Polled","Regis.Electors")
Top<-cSplit(lapply(table1, function(x) str_remove(x,Names)),"hello"," ")
Bottom<-cSplit(lapply(table2, function(x) str_remove(x,Names)),"hello"," ")
Name1<-str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][2],"\r")
Name2<-str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][27],"\r")
Top1<-data.table("ColumnNames"=Names,"Votes"=Top$hello_1,"Percentage"=str_remove(Top$hello_2,"%"))
Bottom1<-data.table("ColumnNames"=Names,"Votes"=Bottom$hello_1,"Percentage"=str_remove(Bottom$hello_2,"%"))
Top1[,2] <- lapply(Top1[,2], function(x) as.numeric(as.character(str_remove_all(x,","))))
Bottom1[,2] <- lapply(Bottom1[,2], function(x) as.numeric(as.character(str_remove_all(x,","))))
Top1[,3]<-lapply(Top1[,3], function(x) as.numeric(as.character(x)))
Bottom1[,3]<-lapply(Bottom1[,3], function(x) as.numeric(as.character(x)))
Electorate1<-data.table("Year"=2015,
"District"=str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][1],
" Districts Results\r"),
"Electorate"=Name1,"ColNames"=Top1$ColumnNames,"Votes"=Top1$Votes,
"Percentage"=Top1$Percentage)
Electorate2<-data.table("Year"=2015,
"District"=str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][1],
" Districts Results\r"),
"Electorate"=Name2,"ColNames"=Bottom1$ColumnNames,"Votes"=Bottom1$Votes,
"Percentage"=Bottom1$Percentage)
output<-rbind2(Electorate1,Electorate2)
return(output)
}After developing such a function and naming it as Extract_twotable(), it now possible to extract data from more than 90 pages in the Presidential election 2015 pdf file.
Using the One Function to extract Data from Multiple pages
In order to do the above extraction first we have to identify the pages which have only one table and then deselect them. After this with the help of a for loop we can create a long list of elements. Where each element is a table, and that table from one page. Below is the code for that solution.
# page numbers from 1 to 111
pages<-c(1:111)
# removing pages with only one tables
pages<-pages[-c(1,10,18,31,48,58,61,64,70,82,87,90,96,99,110,111)]
# creating an empty data-frame
datas<-NULL
# creating the large data frame after extracting two tables
for (i in pages)
{
# two tables of each page is considered as a list element
datas[[i]]<-Extract_twotable(i)
}
# combining the multiple list data-frame as one data-frame
out1<-do.call("rbind",datas)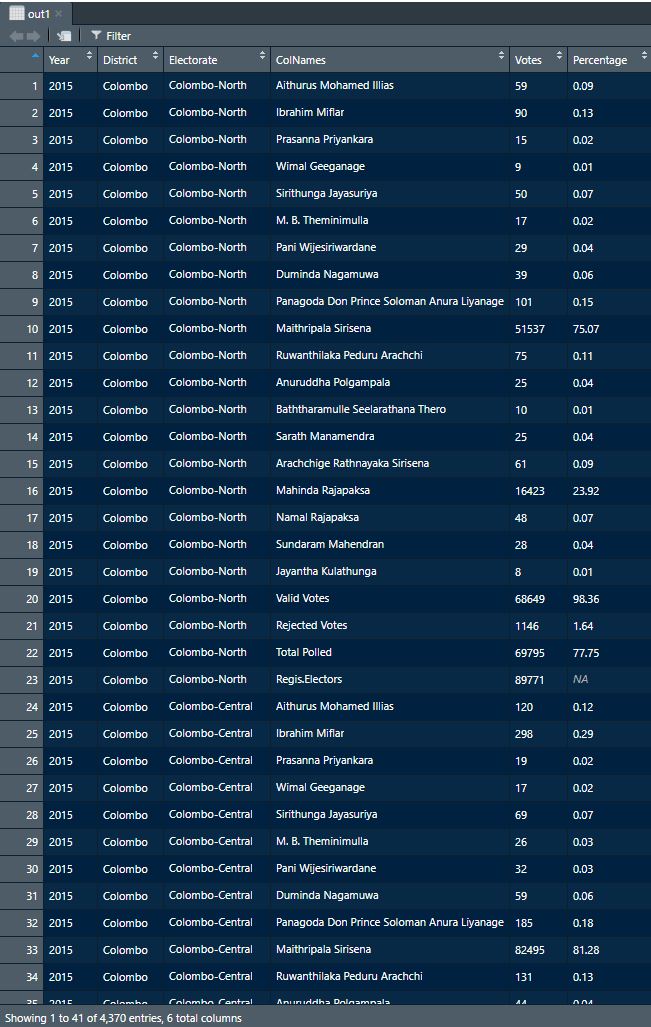
After this large extraction similarly we have to write a function for one table pages also. Below is the code chunk for that. Here we create a function called Extract_onetable() similar as before where the input is page-number.
Extract_onetable<-function(page)
{
table1<-data.table(str_split(SL_PE_2015[[page]],"\n")[[1]][4:26])
names(table1)<-"hello"
Names=c("Aithurus Mohamed Illias","Ibrahim Miflar","Prasanna Priyankara",
"Wimal Geeganage","Sirithunga Jayasuriya","M. B. Theminimulla",
"Pani Wijesiriwardane","Duminda Nagamuwa",
"Panagoda Don Prince Soloman Anura Liyanage",
"Maithripala Sirisena","Ruwanthilaka Peduru Arachchi",
"Anuruddha Polgampala","Baththaramulle Seelarathana Thero",
"Sarath Manamendra","Arachchige Rathnayaka Sirisena",
"Mahinda Rajapaksa","Namal Rajapaksa","Sundaram Mahendran",
"Jayantha Kulathunga","Valid Votes","Rejected Votes",
"Total Polled","Regis.Electors")
Top<-cSplit(lapply(table1, function(x) str_remove(x,Names)),"hello"," ")
Name1<-str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][2],"\r")
Top1<-data.table("ColumnNames"=Names,"Votes"=Top$hello_1,"Percentage"=str_remove(Top$hello_2,"%"))
Top1[,2] <- lapply(Top1[,2], function(x) as.numeric(as.character(str_remove_all(x,","))))
Top1[,3]<-lapply(Top1[,3], function(x) as.numeric(as.character(x)))
Electorate1<-data.table("Year"=2015,
"District"=str_remove(str_split(SL_PE_2015[[page]],"\n")[[1]][1],
" Districts Results\r"),
"Electorate"=Name1,"ColNames"=Top1$ColumnNames,"Votes"=Top1$Votes,
"Percentage"=Top1$Percentage)
output<-Electorate1
return(output)
}After creating this function we focus only on the pages with one tables. Below is how we extract information from such pages and create a large data-frame.
# list of pages with only one tables
pages<-c(10,18,31,48,58,61,64,70,82,87,90,96,99,110)
# creating an empty data-frame
datas1<-NULL
# creating the large data frame after extracting one table
for (i in pages)
{
# one table of each page is considered as a list element
datas1[[i]]<-Extract_onetable(i)
}
# combining the multiple list data-frame as one data-frame
out2<-do.call("rbind",datas1)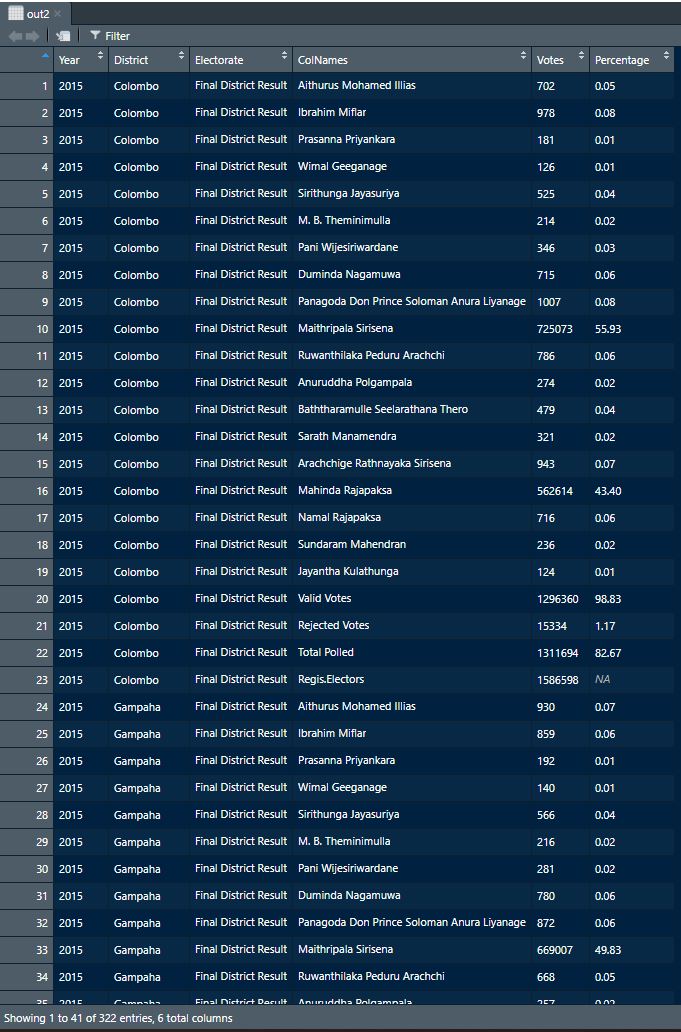
Now we have two data-frames which are named as out1 and out2 which needs to be combined based on rows. The combined data-frame is called Election2015 which has all the information of Presidential Election 2015 pdf file.
# final data frame which has information from the entire pdf
# which means combining the out1 and out2 data-frames
Election2015<-rbind(out1,out2)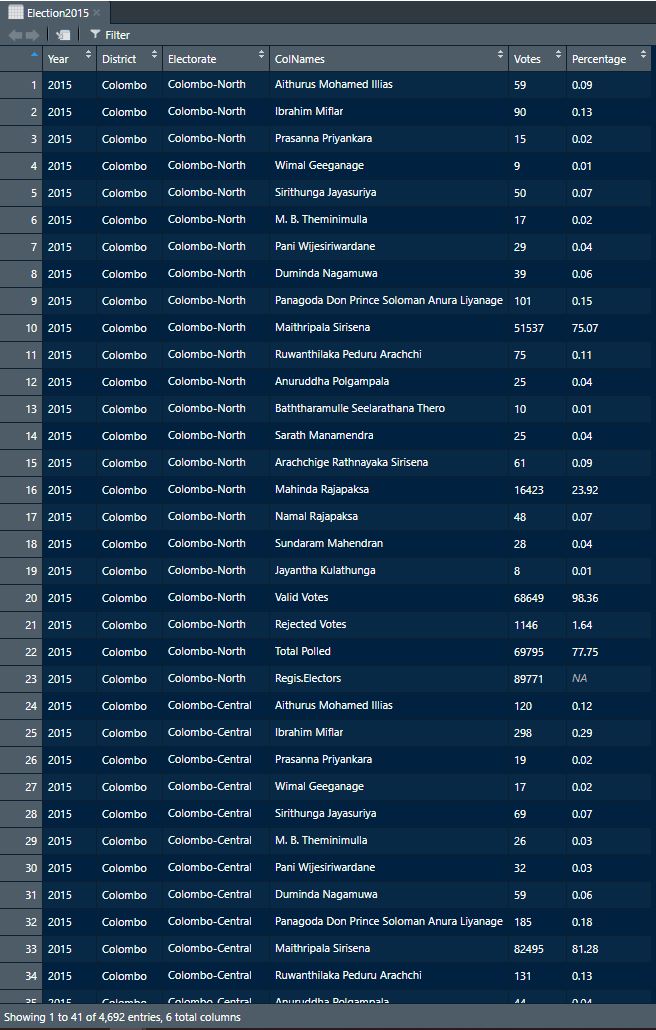
Validating the Data
Even though I claim the data extraction is complete there needs to be validation. I find that it will be reassuring to have some form of validation. Therefore the best way is to tally the votes in individual districts and compare them with the final vote(which is on the last page of the pdf file). I shall focus on the contestants Maithripala Sirisena, Mahinda Rajapaksa and data such as Valid Votes, Rejected votes and Total Polled. Below is the code to find those final votes which will be compared with the pdf file.
# validating final votes of Maithripala Sirisena
ElecFinal2015<-subset(Election2015,Electorate=="Final District Votes" & ColNames=="Maithripala Sirisena" |
Electorate=="Final District Result" & ColNames=="Maithripala Sirisena")
ElecFinal2015[,sum(Votes),by="ColNames"]## ColNames V1
## 1: Maithripala Sirisena 6217162sum(ElecFinal2015$Votes)## [1] 6217162# validating final votes of Mahinda Rajapaksa
ElecFinal2015<-subset(Election2015,Electorate=="Final District Votes" & ColNames=="Mahinda Rajapaksa" |
Electorate=="Final District Result" & ColNames=="Mahinda Rajapaksa")
ElecFinal2015[,sum(Votes),by="ColNames"]## ColNames V1
## 1: Mahinda Rajapaksa 5768090sum(ElecFinal2015$Votes)## [1] 5768090# validating final votes of valid votes
ElecFinal2015<-subset(Election2015,Electorate=="Final District Votes" & ColNames=="Valid Votes" |
Electorate=="Final District Result" & ColNames=="Valid Votes")
ElecFinal2015[,sum(Votes),by="ColNames"]## ColNames V1
## 1: Valid Votes 12123452sum(ElecFinal2015$Votes)## [1] 12123452# validating final votes of rejected votes
ElecFinal2015<-subset(Election2015,Electorate=="Final District Votes" & ColNames=="Rejected Votes" |
Electorate=="Final District Result" & ColNames=="Rejected Votes")
ElecFinal2015[,sum(Votes),by="ColNames"]## ColNames V1
## 1: Rejected Votes 140925sum(ElecFinal2015$Votes)## [1] 140925# validating final votes of polled votes
ElecFinal2015<-subset(Election2015,Electorate=="Final District Votes" & ColNames=="Total Polled" |
Electorate=="Final District Result" & ColNames=="Total Polled")
ElecFinal2015[,sum(Votes),by="ColNames"]## ColNames V1
## 1: Total Polled 12264377sum(ElecFinal2015$Votes)## [1] 12264377If we compare the above results with below table clearly our extraction is successful and the amounts are accurate.
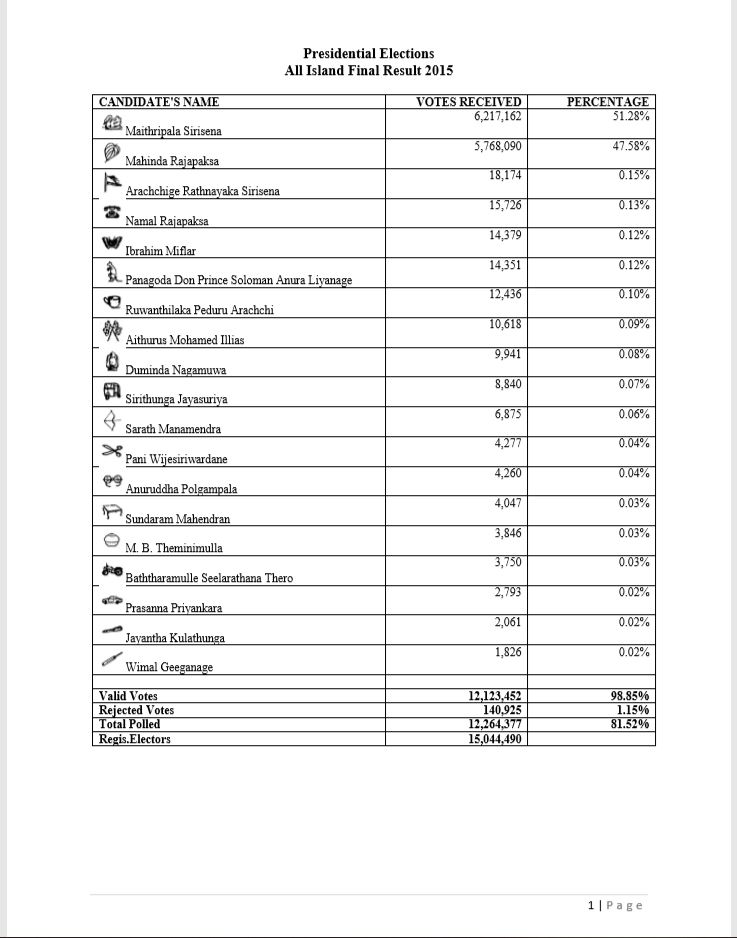
Issues in the pdf file
Satisfying end to be honest, but there was one glitch. If we consider the final district result tables only in one occasion the heading was inconsistent. This occurred for the Kalutara district, it should have been “Final District Result” instead of “Final District Votes”. Rather than that no issues at all. Similarly if we identify some creative pattern step by step it is possible to extract all the presidential election data and create a much more lucrative data retrieval website. Well we could even add the parliament and provincial election results as well.
For now One step at a time.
THANK YOU